서버 가상화 환경에서의 I/O 장치 가상화 방법
전통적인 I/O 장치는 한개의 프로그래밍 인터페이스를 가진다. 하지만, master가 여러개라면? 세가지의 suport option이 지원된다.

서버 가상화 환경에서 I/O 장치를 가상화하려면 다음과 같은 기능들을 가상화해야 한다.
- 인터럽트 처리
- DMA를 위한 MMIO(Memory Mapped I/O)
이 기능들을 구현하기 위해서 다음과 같은 전략들이 시도되었다.
1. 에뮬레이션 - 디바이스 사용
[그림 8. 디바이스 에뮬레이션 도식]
디바이스 에뮬레이션은 기존 OS 드라이버와 호환되는 가상 장치를 만들어 VM에 제공해 주는 방식을 말한다.
에뮬레이션의 가장 큰 장점은 바로 호환성이다. 가상 장치만 제대로 구현된다면 Guest OS 수준에서는 수정할 것이 아무것도 없기 때문에 일반적으로 가장 좋은 호환성을 보이며, 그 때문에 가상 장치는 에뮬레이션 대상 물리 장치의 알려진 버그까지도 동일하게 구현한다.
하지만 인터럽트 또는 I/O가 발생할 때마다 VM Exit가 발생하여 예외 핸들러를 통과해야 하기 때문에, 상당한 성능 저하가 나타난다.
그리고 에뮬레이션 대상 장치를 하이퍼바이저에서 직접 구현해야 하기 때문에, 실질적으로 가상화 환경에서 지원할 수 있는 디바이스의 종류는 제한적이다.
2. 반가상화 - Host OS 소스코드 변경
[그림 9. 디바이스 반가상화 도식]
다바이스 에뮬레이션의 성능 문제를 완화하기 위해 반가상화 방식의 디바이스가 등장하였다.
기본적으로 에뮬레이션된 가상 장치를 VM에 제공하는 것 까지는 동일하나, 장치 드라이버는 자신이 가상화 환경에 있다는 것을 인지하고, 가능하다면 Hypercall을 통해 하이퍼바이저 API에 접근한다. 가상 장치는 더 이상 I/O가 발생할 때마다 VM Exit 를 일으킬 필요가 없으며, 성능도 그만큼 향상된다.
더 높은 수준의 추상화를 가진다.
일반적으로 대량의 I/O가 발생하는 디스크 컨트롤러와 NIC 드라이버를 반가상화 방식으로 구현하게 된다.
보안이슈가 존재한다: 하이퍼바이저가 모든 데이터를 볼 수 있어 guest를 코드를 모두 바꿀 수 있다.
다수의 context switching이 필요하다.
3. Pass-through - guest가 직접 디바이스 사용
앞서 이야기 한 두 방식의 구현을 살펴보고 있으면 한 가지 의문이 생길 것이다.
"I/O 가상화를 위해 필요하다던 MMIO 구현은 어디 있지?"
그렇다. 에뮬레이션과 반가상화 방식으로 구현된 가상 디바이스들은 Host의 물리 디바이스와 MMIO로 직접 통신하지 않는다. 왜냐하면 게스트 OS가 인식하고 있는 장치는 호스트에 연결된 물리 장치가 아니며, 디바이스 드라이버 또한 그 물리 장치를 위해 만들어진 것이 아니기 때문이다.
pass thorugh는 하나의 guest가 I/O device를 직접 talk 한다. 여러 guest가 동시에 사용하지 못하게 passthrough하는 방식이며 device share없이 직접 control 하기 때문에 가장 우수한 형태이다.
예시로 VT-d가 포함된다.
하지만 전용 physical I/O장치가 항상 게스트별로 있기 어렵다.
또한 migration에 나쁘며 모든 Physical이 gPA이다. (gPA가 guest를 host한다.)
이보다 더 나은 방법으로 PCIE IOV (SRIOV) 가 제안된다.
이 방법은 multiple master가 있음을 알고 programming interface를 각각 할당한다.
VFS로 구현되며 migration이 지원된다. 하지만 위에서 본 pass through의 단점과 더불어 특별한 HW가 필요하다는 단점이 존재한다.
이러한 IOMMU 기술을 이용해 가상머신이 하이퍼바이저의 도움없이도 직접 PCI 디바이스에 접근할 수 있게 된다. 이를 PCI Pass-through라고 한다.
해결해야 할 PCI Passthrough 이슈
하지만 여전히 문제가 있다. address와 관련된 문제 , interrupt와 관련된 문제들이 남아있다.
I/O port와 MMIO 공간은 guest에 직접 mapping 되어야 한다.
디바이스 인터럽트는 게스트와 매핑되어야한다.
결론적으로 gPA가 hPA로 변환되어야한다.
guest는 서로 간섭하는 것을 허용해서는 안된다.
Passthrough DMA 문제
가상화일때: 기존 모델에서 guest OS가 guest PA만 알기 때문에 하이퍼바이저가 MMU가 사용하는 paging structure를 set up 해야한다.
: 가상머신의 운영 체제는 액세스하고 있는 실제 물리 주소를 알 수 없다. 따라서 IOMMU 없이 PCI 디바이스에 직접 특정 물리 주소에 DMA하도록 지시할 수 없다. 하지만 IOMMU 기술을 통해 가상머신의 OS가 PCI 디바이스에게 가상주소로 DMA를 요청하더라도 IOMMU를 통해 실제 물리 주소로 변환되어 정상 작동하게 된다.(gPA → hPA)
이에 대한 해결책은 IOMMU (DMAR)이다
→ An MMU is needed for DMA accesses: IOMMU
- Intel calls it a DMA Remapping Engine (DMAR)
The IOMMU needs to know the gPA → hPA for ALL Guests
DMA Remapping
- VMM은 리맵 테이블을 설정할 수 있으며 하드웨어가 DMA 읽기/쓰기 패킷을 가로채고(INTERCEPT) *주소를 즉시 *번역(TRANSLATE) 할 수 있도록 지원합니다.
- 로직에는 CPU 페이징에 사용되는 IOMMU 및 페이지 테이블이 포함.
- 페이지 테이블은 live in DRAM
DMA 리매핑을 통해 게스트가 VMEXIT 없이 DMA 트랜잭션을 설정할 수 있다.
- PCI 패스스루 디바이스 드라이버는 정확히 그대로 설정된다.
[그림 11. DMA Address Translation 도식]
위 그림은 VT-d에서 DMA Address Translation을 처리하는 방식에 대한 아이디어를 보여준다. 동일한 DMA 주소 영역을 가진 장치 두 개는 서로 다른 도메인에 할당되며, 서로 다른 호스트 페이지 주소에 매핑된다.
이 때, 도메인이란 Address Isolation을 제공하는 범위를 말한다. 장치가 도메인 단위로 할당되면, 하나의 도메인에 속한 여러 VM들이 동일한 장치를 공유하는 Virtual Function 기능을 구현할 수 있다.
서로 다른 도메인에 속한 장치는 서로 통신할 수 없으며, 이것은 단순히 허용되지 않은 메모리 범위로의 접근을 차단하는 방식으로 구현된다.
DMA Request의 주소 변환은 DMA Remapping hardware가 전적으로 담당하며, 이 동작은 디바이스와 OS에게 투명하게 이루어진다.
그렇다면, 장치는 실제로 어떻게 올바른 목표 호스트 페이지를 찾을 수 있을까?
[그림 12. Device to Domain Mapping 도식]
PCI-E Transaction Layer Header에는 해당 요청을 발행한 장치의 PCI-E 버스 번호, 장치 번호, Function 번호가 포함되어 있다.
DMA Remapping hardware는 이 정보를 참고하여 도메인별 페이지 테이블을 유지한다. 페이지 테이블 탐색 방식은 PML4 탐색과 동일하며, Remapping hardware는 2MB/1GB Hugepage를 지원한다.
MMU에서의 Table walkthrough와 마찬가지로, DMA Remapping 또한 별도의 TLB(Table Lookaside Buffer)를 갖는다. 기본적으로 TLB는 DMA Remapping Hardware에 존재하지만, 크기가 제한적이기 때문에 해당 플랫폼에서 Active 된 DMA Remapping target 수와 DMA Address locality의 영향을 심하게 받는다.
이러한 잠재적인 확장성 문제를 해소하기 위한 방법으로 Device TLB가 제안되었다.
[그림 13. Device TLB 개념 도식]
이 기능은 PCI-E Base Specification 4.0 이후의 ATS(Address Translation Service)에서 지원된다.
Interrupt Remapping
DMAR은 인바운드 메모리가 IOMMU 사이드에서 쓰일지, Interrupt remapping side에서 쓰일지 결정해야 한다. → memory write일때 그러면 트랜잭션은 MSI가 되어 인터럽트 리매핑 로직에 의해 처리됩니다.
Info in MSI is used as an index into IRT
장치에서 발행한 인터럽트를 올바른 VM에 전달하기 위한 Interrupt Remapping 또한 하드웨어적으로 지원된다.
[목적]
보안 요구 사항을 지원하려면 소프트웨어가 I/O 장치가 프로세서에 대한 인터럽트를 생성하지 못하도록 제한할 수 있는 방법이 있어야 합니다.
가상화 성능을 개선하려면
- 한 프로세서에서 다른 프로세서로 인터럽트를 마이그레이션하는 더 간단한 방법 제공
- 각 가상 머신이 자체 인터럽트 벡터 공간(가상 벡터)을 가질 수 있도록 허용
➔ 인터럽트 포스팅 지원(나중에 다룸) - 게스트에게 가상 인터럽트를 제공할 때 하이퍼바이저의 개입을 줄입니다.
➔ 인터럽트 포스팅 지원(나중에 다룸)
이 때, 장치는 Remappable Format Interrupt Request를 발행해야 한다.
!
[그림 14. Remappable Format Interrupt Request의 Address Field 설명]
Compatible Format과의 차이점은 바로 Handle로, 후술할 Interrupt Remapping Table을 참조하기 위해 사용된다.
Interrupt Remapping Hardware는 메모리에 위치한 IRT(Interrupt Remapping Table)을 통해 이 기능을 수행한다. IRT는 1단계 테이블 구조를 가지고 있으며, 테이블의 위치와 크기는 IRTAR(Interrupt Remap Table Address Register)을 통해 지정된다.
[그림 15. IRTAR 구조 (Intel)]
위 표에서 알 수 있듯이 IRTE(Interrupt Remapping Table Entry)의 최대 크기는 65535 이다.
그렇다면 IRTE는 어떤 구조를 가지고 있을까?
!https://velog.velcdn.com/images/sjuhwan/post/01c42032-e1e9-409a-a539-89c04f6a96fd/image.png
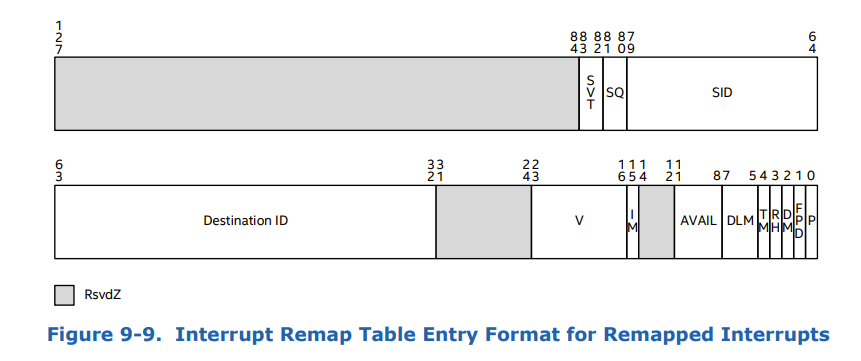
[그림 16. Interrupt Remapping Table Entry 구조]
위 128비트의 구조체 중 우리가 관심을 가질 부분은 SID (Source Identifier)와 Destination ID이다.
[그림 17. IRTE의 Source ID와 Destination ID 설명]
xAPIC의 경우, 8비트짜리 APIC Destination ID가 보인다. 이것은 CPU의 ID를 나타내는 것으로, xAPIC의 CPU Core 확장성이 최대 256개였기 때문에 인텔은 이 제한을 해소한 x2APIC를 만들었다.
위 표에서 확인할 수 있듯이, x2APIC에서는 32비트의 APIC Destination ID를 가진다.
즉, 장치에서 발행한 Interrupt Request는 IRT -> IRTE -> APIC Destination ID를 따라 목적지인 물리 CPU에 전달되는 것이다.
더 좋은 솔루션은 없는가? (46-)
Interrupt Posting
Interrupt remapping을 통해 장치에서 발행한 Interrupt Request를 VM에 전달할 수 있게 되었으니 이제 우리가 원하던 기능은 모두 구현된 것이 아닐까?
기능은 모두 구현된 것이 맞지만, 아직 중요한 문제가 하나 남아있다. 바로 성능이다.
Interrupt Remapping에서 볼 수 있듯이, IRTE에 기록된 Destination ID는 pCPU ID이다. 다시 말해 인터럽트는 '특정 물리 CPU'로 전달된다는 것이다.
하지만, 가상머신의 경우 vCPU가 실행되는 pCPU는 고정되어 있지 않다. 그렇기 때문에 vCPU 스케줄링 과정에서 다음과 같은 문제가 생긴다.
- VMX는 pCPU에 도착한 인터럽트 요청이 어떤 VM을 목표로 도착한 것인지 확인하고, vCPU를 깨워야 한다
- VM의 vCPU가 다른 pCPU로 마이그레이션 되면 IRTE의 Destination ID도 함께 업데이트 되어야 한다
- 만약 다른 pCPU에 위치한 VM을 목적지로 한 인터럽트 요청이 도착하면 IPI를 통해 해당 pCPU를 깨워야 한다
vCPU가 Oppertunistic하게 여러 pCPU 사이를 이동한다는 점을 감안하면 성가신 일이며, Remapped interrupt가 발생할 때 VM Exit가 실행되어야 한다는 것 또한 상당한 오버헤드를 가져온다. → 이 문제를 해결하기 위해 인텔은 VT-d에 Interrupt Posting을 도입하였다. (60p.)
[그림 18. Posted Interrupt 개념 (Intel)
위 그림에서 보이듯이 Interrupt Posting 모드의 장치 인터럽트가 IRTE를 찌르면 IRTE는 vCPU의 Posted Descriptor를 가리키게 된다.
[그림 19. Posted Interrupt Descriptor 구조]
A PID can be created for each virtual APIC by Hypervisor
Posted Descriptor는 64바이트로 정렬된 구조체로, Posted Interrupt를 기록하기 위해 사용된다.
VMCS는 NDST(Notification Destination = APIC Dest ID)-NV(Notification Vector = pCPU IVT ID) 쌍을 통해 Notification Event를 발생시키고, 최종적으로 Posted Interrpt Descriptor에 지정된 Vector(=pCPU IVTE, 8비트)의 Interrput Vector를 트리거 하여 pCPU에서 실행시키게 된다.
이제 vCPU가 마이그레이션 될 때에도 IRTE를 변경할 필요가 없으며, 개별 VM의 원자적 마이그레이션이 가능해진다. 즉, vCPU가 마이그레이션 될 때, VMM은 타겟 pCPU의 IVT에 ANV를 추가하고, PD의 NDST와 NV만 변경하면 된다.
그리고 Interrupt Event 수신이 VM 컨텍스트에서 발생하기 때문에 더 이상 인터럽트가 VM Exit를 발생시키지 않음으로써 VM 성능이 향상된다.
'Cloud' 카테고리의 다른 글
| UTM을 통해 Apple Silicon Macbook에 Ubuntu ARM64 설치 (0) | 2024.08.15 |
|---|---|
| [클라우드 컴퓨팅] DB (0) | 2024.01.19 |
| [클라우드 컴퓨팅] 컨테이너와 ECS (0) | 2023.12.05 |
| [클라우드 컴퓨팅] Intro (0) | 2023.10.24 |
| [Virtualization 101] 1. Introduction (0) | 2023.10.17 |



{kind=link}
댓글