클라우드 컴퓨팅을 배우며, 가상화라는 단어가 얼마나 무서운 단어인지 깨닫게 되었다. 하드웨어, 네트워크 등 수많은 CS 지식을 아주 복잡하고 깊은 수준까지 연결하여 최종적으로 만들어 낸 산물 같은 느낌이다. 하지만 이번에 클라우드 컴퓨팅에서 다양한 내용을 접하며 가상화의 개념에 대해 0.000000000001프로 정도는 이해한 것 같다는 생각이 들어, 잊기 전에 이를 아주 쉽게 정리해보고자 한다.
아래는 아직 완전히 정리가 되지 않았다...!
가장 먼저, 가상화를 가능하게 하는 하이퍼바이저(Hypervisor), 하이퍼바이저에 의해 제어되며 각종 애플리케이션을 실행하기 위한 컴퓨팅 환경인 가상 머신(Virtual Machine, VM)으로 구성된다.

이때 중간에 위치한 MMU는 Memory Management Unit으로, 가상주소를 물리주소로 변환한다.
OS가 PageTable에 가상 물리 주소 사이를 mapping한다. page Table 하나가 4KB의 페이지 크기만큼 memory를 차지하게 된다.
Deep Dive to Hypervisor (VMM)
하이퍼바이저는 Guest OS를 위한 일종의 가짜 하드웨어이다. 이는 크게 두가지 방식으로 나뉜다.
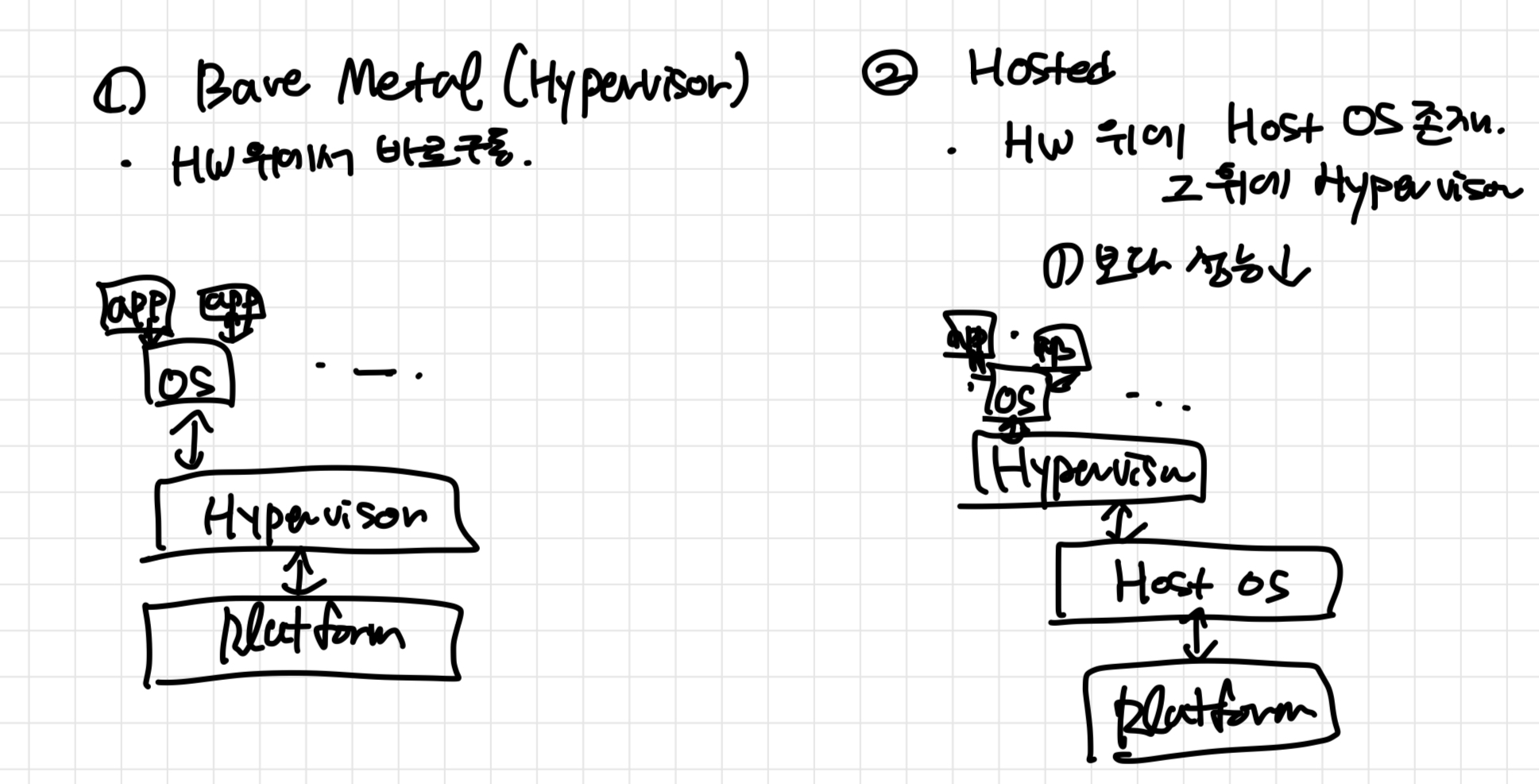

(1) Type 1 - hypervisor (Bare Metal)
| 네이티브 방식으로도 불린다. 물리시스템 위에 하이퍼바이저가 설치되는 방식으로, HW 위에서 바로 구동된다.
- 베어 메탈(Bare-metal) 기반으로 하드웨어 위에서 바로 구동되며, 하이퍼바이저가 다수의 VM들을 관장하는 형태. ‘하이퍼바이저형’으로 불림
- 가상머신에 설치된 게스트 운영체제(Guest OS)는 하드웨어 위에서 하이퍼바이저 다음으로 바로 구동됨
- Type2보다는 더 향상된 성능을 제공하지만, 여러 하드웨어 드라이버를 세팅해야 하며 설치가 어려움
(2) Type 2 - Hosted Architecture
| 물리적 자원을 여러대의 가상 자원(= 독립적이고 논리적인 컴퓨터 자원)으로 관리한다. 이를 통해 가상 컴퓨터를 만들어 작업을 처리한다.
- 하드웨어 위에 호스트 운영체제(Host OS)가 있고, 그 위에서 하이퍼바이저가 다른 응용 프로그램과 유사한 형태로 동작
- 하이퍼바이저에 의해 관리되는 가상머신의 게스트 OS는 하드웨어 위에서 호스트 OS, 하이퍼바이저 다음인 3번째 수준에서 구동됨
- 기존의 컴퓨터 환경에서 하이퍼바이저를 활용하는 거라 설치가 용이하고 구성이 편리한 장점이 있으나 Type1 보다는 성능이 낮음
하이퍼바이저에 의해 분리된 가상 컴퓨터들은 서로 영향을 주지 않으며, 물리적 시스템에도 영향을 주지 않는다. 이는 시스템의 안정성을 향상한다.
+ 가상 메모리와 페이지 테이블

그림은 가장 기본적인 가상 메모리 구조다. 그림을 살펴보면 가상 메모리를 구현한다는 것은 결국 메모리 주소를 속이는 것으로 볼 수 있다.
CPU가 내보내는 메모리 주소, 즉 운영체제나 애플리케이션이 사용하는 주소는 실제 메모리의 물리 주소Physical Address가 아닌 가상 주소Virtual Address다. 따라서 가상 메모리를 구현하려는 CPU 제조 업체는 저마다 하드웨어 관점에서 가상 주소를 물리 주소로 변환하는 MMUMemory Management Unit라는 것을 제공한다.
가상 주소와 물리 주소와의 매핑을 결정하는 것은 페이지 테이블 Page Table이다. 운영체제는 가상 주소와 물리 주소 사이의 매핑 정보를 페이지 테이블에 기록한다. 그런 다음 CPU의 페이지 테이블 베이스 레지스터Page Table Base Register가 페이지 테이블에 기록한 메모리 주소를 등록하면, MMU는 페이지 테이블을 검색해 CPU가 내보내는 가상 주소의 실제 물리 주소를 찾아내 변환하고, 변환한 주소를 통해 메모리에 접근한다. 즉, 페이지 테이블은 가상 주소와 물리 주소 사이의 변환 테이블이다.
PCI configuration space는 PCI, PCI-X, PCI Express의 버스에 삽입된 카드의 configuration을 자동으로 설정하는 기본 방법이다. 장치를 사용하려면 장치가 어떤 것이고(identification), 어떤 장치와 어떻게 통신해야되는지(protocol)를 알아야 하는데, PCI 버스에서는 장치를 인식하고, 장치의 기본적인 정보를 얻기 위하여 PCI configuration space를 사용합니다. 쉽게 말하면 Device ID, Vendor ID, Class code 와 같은 다양한 정보들이 담겨있는 구조체이다.
PCI local bus가 다른 I/O 아키텍처에 비해 크게 개선된 것 중 하나는 configuration mechanism이다. normal memory-mapped 와 I/O port space 이외에도 버스 위의 각각의 device function은 configuration space를 가지고 있다. configuration space는 256바이트 길이이며, 주소를 지정할 수 있는 8비트 PCI bus, 5비트 장치, 3비트 function 번호를 가지고 있다. 이 는 BDF(Bus/Device/Function) 라고도 합니다.
→ 주소 접근을 위한 identify id인 것.
→ Hypervisor가 해당 주소를 사용해서 fake HW를 생성한다.
가상화의 복잡성
게스트 os에서 잠재적으로 유해한 작업을 가로채거나 피하는 데 사용되는 여러 소프트웨어 기술들이 존재한다. 이를 크게 세가지로 분류하면
1. Ring De-privileging (반특권모드? 비특권모드? 한국어로 뭐라고 하는지 모르겠다.)
2. Paravirtualization (반가상화)
3. Binary Translation(이진 변환)
으로 나눌 수 있다.
모든 시굴들이 trap and emulate procedure 이나 코드교체 과정에 의존적이다. -> 따라서 가상화 환경 제공을 위해 SW Overhead와 complexity를 발생시킨다.
Ring Deprivileging (Ring Alisasing)
- Guest OS를 더 작은 특권 레벨에서 run하는 것. 특권있는 민감한 작업은 예외를 발생시킨다. (= trapped)
- 또한, 무조건 VM이 OS보다 낮은 권한을 갖는다.
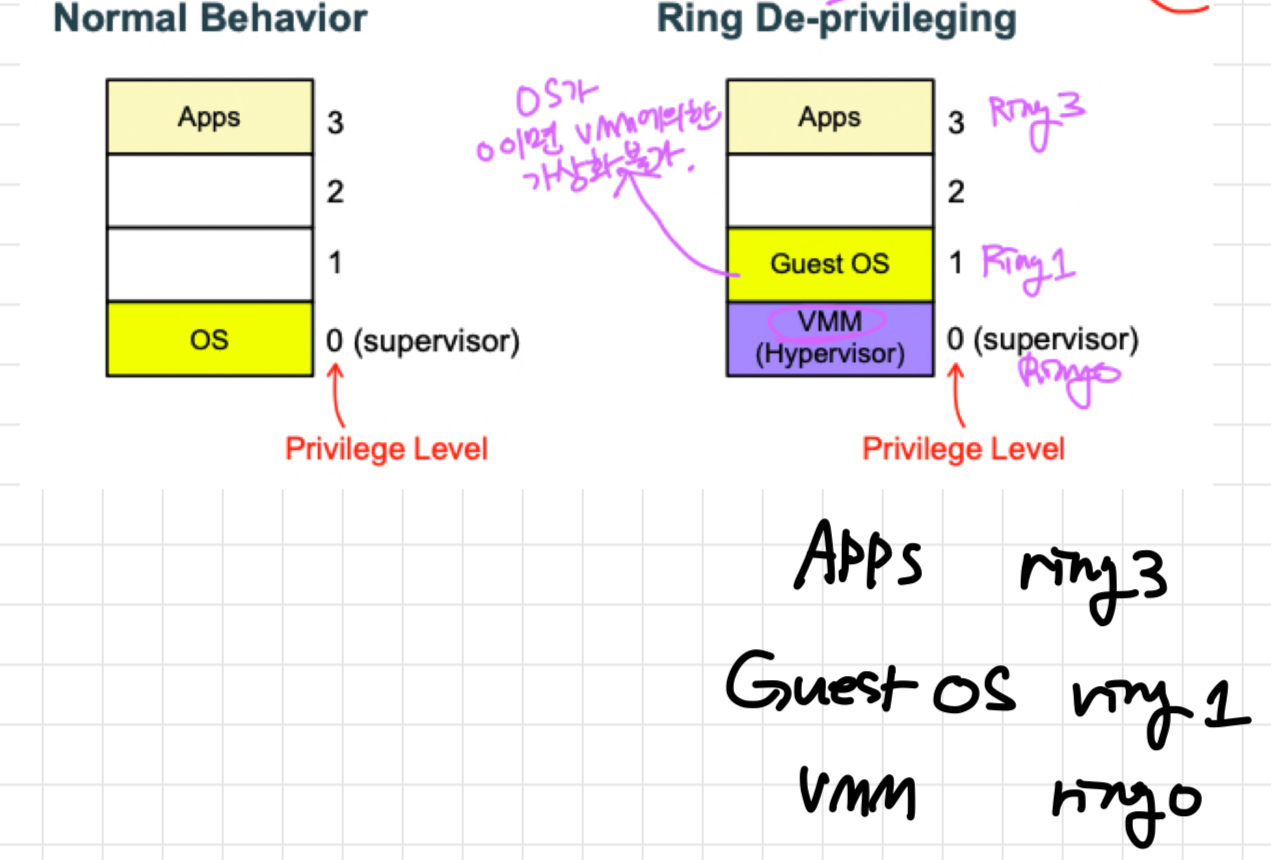
이 개념을 설명하려면 먼저 OS의 특권 모드(Privileged Mode)와 protection Ring에 대해 아는 것이 중요하다.
OS가 제공하는 가장 핵심적인 기능은 하드웨어 리소스의 스케줄링이다. OS가 제한된 자원을 독점하며, 응용 프로그램은 해당 자원이 필요할 때 OS의 System Call을 통해서 OS에게 제어권을 넘기고, OS가 해당 요청을 완료한 다음 다시 응용 프로그램을 실행한다.
이 때, 커널은 특권 모드(Privileged Mode)에서 동작하기 때문에 리소스가 한정되어 있는 하드웨어에 독점적으로 접근할 수 있는 권한을 가지고 있다. 즉, 커널이 리소스 스케줄링이라는 핵심 기능을 수행하기 위해 필요한 것이 바로 실행 모드의 구분과 특권 모드인 것이다.
이제 본론으로 돌아가, VMM의 관점에서 이 개념을 다시 생각해 보자.
VM의 OS(이하 Guest OS) 커널은 자신이 특권 모드에서 동작하고 있다고 생각하고, 특권 모드에서 사용할 수 있는 명령어를 실행할 것이다. 하지만 실제로 특권 모드에서 실행되는 것은 VMM이기 때문에 Guest OS 커널이 실행하는 특권 명령어는 Exception(Trap)을 일으킬 것이다.
VMM은 CPU의 Exception handler의 실행 주소를 자신의 Exception handler로 설정하여 Guest OS에서 발생한 특권 모드 명령어를 정상적으로 처리한 뒤 실행 컨텍스트를 VM에게 반환한다.
이렇게 하이퍼바이저가 Guest OS에서 발생하는 Trap을 가로채서 VM에 맞게 에뮬레이션 하는 것을 De-privileging이라 한다.
IA-32에서 운영체제는 Ring 0, 애플리케이션은 Ring 3 권한으로 동작한다. 하지만 가상화 환경에서는, 하드웨어와 직접 연결되어 가상화를 수행하는 VMM이 Ring 0 권한으로 실행돼야 한다. 이때, 운영체제도 동일하게 Ring 0 권한으로 실행되면 운영체제가 VMM 코드를 제어할 수 있을 뿐만 아니라 VMM에 의한 가상화 자체가 불가능해 진다. 따라서 운영체제는 VMM보다 낮은 권한을 부여한다. 이러한 작업을 Ring Deprivileging이라고 하는데, Ring Deprivileging은 다음과 같은 두 가지 형태로 수행된다.
♦ VMM : Ring 0
Guest OS : Ring 1
App : Ring 3
♦ VMM : Ring 0
Guest OS : Ring 3
App : Ring 3
이렇게 운영체제의 실행 권한이 하향 조정됨으로써 야기되는 문제점 때문에 VMM의 역할 비중이 커졌다. 즉 운영체제가 하드웨어에 접근하는 작업이나 특정한 시스템 콜과 같이 Ring 0 권한이 요구되는 작업을 모두 모니터링해서 그에 맞는 작업을 수행해야 한다.
동시에 여러 개의 운영체제가 동작 중이라면 이들에 대한 Context Switching을 VMM이 담당해야 한다. 실행권한 변경에 따른 문제점을 극복하기 위해서 Paravirtualization, Binary Translation 등의 방법들이 이용됐다.
하지만 Paravirtualization은 운영체제의 커널을 수정해서 특정한 VMM에서 가상화가 가능하도록 하는 것인데, 이는 리눅스와 같은 오픈소스 운영체제에서나 가능한 일이며 일반적으로 적용할 수 있는 방법이 아니다.
또한 Binary Translation은 상대적인 성능상의 부하가 문제가 된다. 이런 소프트웨어 가상화에 의한 문제점을 해결해 주는 것이 CPU 레벨의 가상화라고 할 수 있다. 즉 가상화를 구현하기 위해서 사용된 Paravirtualization, Binary Translation과 같은 작업을 CPU 레벨에서 지원하는 것이다.
Paravirtualization ( 반 가상화)
- Guest의 소스 코드를 수정(modify)하는 것이 목적이다. -> 가상화 환경에서 실행되고 있다.
- 이 수정이 API를 통해 hypervisor에 대한 호출(hypercall)로 중요한 instruction을 대체할 수 있다.
- Guest OS가 Hypercall을 통해 직접 hypervisor에 요청을 날리기 때문에, 자기 자신이 Guest OS임을 인지하고 있다.
Para Virtualization은 한글로 반가상화라고도 하는데, 핵심은 Hyper Call이다. Para Virtualization에 사용되는 Guest OS는 Hyper Call이라는 인터페이스를 통해 하이퍼바이저에 직접 요청을 날린다. 방식은 사실 OS에서 Application이 커널에게 system call로 서비스를 요청하는 방식과 동일하다. 요청을 날리는 주체가 Guest OS이고, 받는 대상이 하이퍼바이저라는 점이 다를 뿐이다.
전가상화에서의 Guest OS는 자신이 Guest OS인지 모른다고 하였다. 하지만 반가상화에서는 Guest OS가 Hypervisor에 직접 Hyper Call을 날려야 하기에, 자신이 Guest OS라는 사실을 인지해야만 한다. 따라서 반가상화 하이퍼바이저에 올라가는 Guest OS는 커널을 수정하여, Guest용 OS를 따로 만들어야 한다.
따라서 반가상화를 위해서는 중요한 명령어와 아닌 명령어를 구분할 수 있어야 하는데, 그렇기에 Guest OS의 커널의 수정이 필요한 것이다. 그리고 Guest OS가 하이퍼바이저에게 명령어를 가상화해달라고 직접 요청하는데, 이게 Hyper Call이다.
Guest OS가 아니라 VMM에서 실행되어야 하는 명령을 위한 Hypercall 인터페이스를 구현하였다. 예를 들어, Xen의 Guest OS는 CR3 레지스터에 직접 접근할 수 없고, EFLAGS를 업데이트 할 수 없다. 대신 커널에서 Hypercall을 호출하여 해당 작업을 수행해야 한다.
Binary Translation(이진 변환)
- binary(실행파일)을 수정해서 민감한 작업을 hypervisor에 대한 call로 대체하거나 patch한다.
- Guest OS가 특권 명령 수행 시 hypervisor가 바이너리 연산을 통해 HW가 인식할 수 있는 명령어로 변환하여 전달한다.

Trap & Emulate 방식의 단점을 해결하기 위해 VMware에서는 이진 변환(Binary Translation)이란 기술을 선보였습니다. 이진 변환이란 게스트 OS에서 특권 명령을 수행하려고 할 때 하이퍼바이저가 바이너리 연산을 통해서 하드웨어가 인식할 수 있는 명령어로 변환하여 전달하는 기법이다. 이진 변환이란 CPU에서 직접 실행하는 방식이지만 중간에 하이퍼바이저가 번역하는 과정이 추가되었다. 이러한 방법은 개발하기가 상당히 까다롭다는 단점이 있었다.
VMware가 선보인 이진 변환이라는 기술과 다르게 Xen은 Hypercall이라는 방법을 제안하였는데, 반가상화라는 대비되는 명칭을 갖게 되었다.
HW help for Virtualization
인텔이 가상화 제공의 성능과 효율성 개선을 위해 프로세서에 하드웨어 개선 사항을 추가한 것을 통칭하여 intel-VT라고 부른다.
VT-x : VM에 우선순위 부여하여 병목현상 방지
VT-d : VM에서 직접 IO엑세스가 가능하며 HW적으로 안정된 가상화
Vt-i : CPU processor 쪽으로 Itarium에서만 지원
TXT/TET : Trusted Execution Technology. 신뢰 실행 기술로, SW공격으로부터 시스템 방어
이는 CPUID 명령을 통해 VMX feature를 확인할 수 있다.
CPUID.1 : EVX.VMX[bit5] = 1일때 지원이 되는 것이다.
Intel VT-x
- VMX가 존재한다. hypervisor와 VM이 동작하는 환경을 구분한다.
인텔 VT-x 개요
- VT-x는 가상화를 지원하는 새로운 개념인 VMX Operation이 존재- 하이퍼바이저와 가상 머신이 동작하는 환경 구분
- VMX root Operation: CPU나 하드웨어의 모든 제어권을 가진 오퍼레이션.
- VMX non-root Operation: 특정 명령어 실행과 하드웨어 제어권한이 일부 제한된 오퍼레이션 (Virtual Machine)
- VMX root Operation과 non-root Operation이 서로 전환하는 것을 VMX 전환이라고 한다.
VMCS
VMCS는 VMXdml Non-Root모드의 동작/작동을 정의한다.
- VMX의 Non-Root 모드로의 전환(transition of into / out)을 관리한다.
VMCS: Intel VT-x Example (Operation ex)
VMX Non-Root Operation 및 VMX Transition 은 VMCS 라는 데이터 구조에 의해 제어된다.
VMCS에 대한 접근은 VMCS 포인터를 통해 관리된다.(논리 프로세서당 하나씩)
VMPTRST 및 VMPTRLD 명령을 이용하면 VMCS 포인터를 저장하고 로드할 수 있다. (VMPTR = VMCS Pointer, ST = Store, LD = Load)
VMREAD, VMWRITE, VMCLEAR 명령을 이용하면 VMCS 의 필드를 구성할 수 있다. 아래에서 좀 더 자세하게 다룹니다
https://docs.hyperdbg.org/tips-and-tricks/considerations/basic-concepts-in-intel-vt-x
System memory management
자신만의 가상 주소 공간에서 실제 물리 공간에 매핑된다.
일반적인 Native System memory management에서는 paging table을 통해 Virtual Address가 Physical Address에 매핑된다.
가상화에서는 이와 다르다.
변환 과정에서 가상머신이 생각하는 주소를 실제 Physical Addr로 변경하는 2단계가 필요하다.
guest Virtual Addr → guest Physical Addr → Host Physical Addr 로 2단계 존재.
문제는 guest OS가 반드시 그들이 보는 Addr space를 handle 해야 한다.
하이퍼바이저가 실제로 실제 물리 메모리를 컨트롤하게 되는 것이다.
→ 이 구조에서 기존의 CR3 참조만으로는 GVA를 HPA로 변환할 수 없다. CR3가 더 이상 물리 메모리 주소를 직접 참조할 수 없기 때문이다.
이 부분에 대해 두가지 해결책이 있다.
Shadow 페이지 테이블 : SW only 솔루션
- Page Table이 아닌, 하이퍼바이저가 관리하는 Shadow Page Table로 바꿔치는 것이다. 이렇게 하면 MMU가 Shadow Page Table을 walk하여 HPA를 가져오게 된다.
- 게스트 운영체제에서 사용하는 주소와 실제 머신 물리 주소 간의 translation을 수행함. Shadow 페이지 테이블은 각 게스트 운영체제가 실제로 접근할 수 있는 머신 물리 주소로 변환되어 수정됨
이 기법의 단점은 오버헤드가 크다는 것이다. 가장 먼저, 하이퍼바이저는 VM 내부에서 실행되는 프로세스마다 하나의 페이지 테이블을 유지해야 한다. 실행되는 VM과 프로세스가 늘어날수록 페이지 테이블을 저장하고 관리하는 오버헤드가 점점 더 커지는 것이다.
또한 하이퍼바이저는 게스트 OS가 바라보는 페이지 테이블 구조를 쉐도우 페이지 테이블과 항상 동기화 할 책임을 가진다. 이는 게스트 OS가 페이지 테이블 엔트리를 변경할 때마다, 하이퍼바이저가 해당 동작을 캐치하고 Shadow page table을 업데이트 해야 한다는 것을 의미한다. 이 동작은 페이지 테이블 엔트리에 쓰기 금지 보호를 걸어두는 것으로 구현할 수 있다.
VMM은 내부 데이터 구조에서 PPN→MPN 매핑을 유지하고 하드웨어에 노출된 섀도 페이지 테이블에 LPN→MPN 매핑을 저장한다.
- 최근에 사용된 LPN→MPN 변환은 TLB에 캐시
VMM은 이러한 섀도 페이지 테이블을 게스트 페이지 테이블과 동기화 상태로 유지
→ 게스트가 페이지 테이블을 업데이트할 때 가상화 오버헤드 발생
이를 해결하기 위한 접근 및 dirty bit 동기화 필요
shadow page에 있는 mapping을 guest 가상 주소 그래서 실제 physical 물리 메모리의 주소를 갖는 형태의 매핑은 한게 shadow page table이다.
→ Shadow page table은 가상 메모리 주소와 그 가상 주소에 대응하는 실제 물리 메모리 주소 간의 매핑을 제공하는 데이터 구조입니다. Guest 가상 주소를 실제 물리 메모리 주소로 변환하는 역할을 합니다.
중첩 페이지 테이블
AMD는 Nested Page Table 이라고 하고, Intel은 Extended Page table
기존의 가상 메모리가 가상 주소에서 물리 주소로 변환하는 기능을 하드웨어적으로 구현한 것이라면, 중첩 페이지 테이블은 물리 주소에서 머신 주소로 변환하는 기능을 하드웨어적으로 구현한 것이다.
즉, CPU가 내보내는 가상 주소는 게스트 운영체제가 구축한 페이지 테이블을 통해서 물리 주소로 변경하고, 변경한 물리 주소는 다시 하이퍼바이저가 구축한 중첩 페이지 테이블을 통해서 머신 주소로 변경해 메모리에 접근한다. 이렇게 되면 게스 트 운영체제는 페이지 테이블을 구축할 때 섀도 페이지 테이블이나 직접 접근 방식 에서 발생하던 페이지 폴트 같은 부가적인 오버헤드 없이 페이지 테이블을 구축할 수 있다. 즉, 하이퍼바이저가 게스트 운영체제를 생성할 때 할당해준 메모리의 머 신 주소 정보만 중첩 페이지 테이블에 적어주면 쉽게 메모리 가상화를 할 수 있다.
또한 섀도 페이지 테이블은 모든 게스트 운영체제의 프로세스에 페이지 테이블을 중복해서 유지해야 하지만, 중첩 페이지 테이블은 가상 머신 당 중첩 페이지 테이블 하나만 있으면 되므로 메모리 공간의 활용 효율성 측면에서도 매우 뛰어나다.
VPID Virtual process identifier
하지만 EPT가 장점만 가지고 있는 것은 아니다. TLB miss 시 4번의 메모리 접근이면 충분했던 비 가상화 환경과는 달리, EPT를 활성화하게 되면 한번의 메모리 접근에 최대 24회의 실제 메모리 접근이 필요할 수 있다.
이것은 다시 말해 TLB Flush의 코스트가 훨씬 커진다는 것을 의미한다. EPT의 오버헤드를 최소화하려면, TLB Flush를 최소화해야 한다.
이 점 때문에 인텔은 네할렘 아키텍처에서 EPT와 함께 VPID를 추가하였다.
VPID는 TLB Entry에 추가되는 16비트 식별자로, 개별 가상 머신의 TLB 엔트리를 식별하기 위한 목적으로 동작한다. VMX가 활성화되지 않으면 VPID는 항상 0으로 설정되나, VMX 활성화 시 0번은 VMM이, 1-65535는 VM이 사용한다.
이렇게 VPID와 PCID를 조합하는 것으로, VMM은 VM 전환 시 TLB Flush 없이도 개별 프로세스의 TLB Entry의 일관성을 유지할 수 있게 되었다.
'Cloud' 카테고리의 다른 글
| UTM을 통해 Apple Silicon Macbook에 Ubuntu ARM64 설치 (0) | 2024.08.15 |
|---|---|
| [클라우드 컴퓨팅] DB (0) | 2024.01.19 |
| [클라우드 컴퓨팅] 컨테이너와 ECS (0) | 2023.12.05 |
| [Virtualization 101] 2. Vt-d (0) | 2023.10.29 |
| [클라우드 컴퓨팅] Intro (0) | 2023.10.24 |



댓글