728x90
자료구조에 대한 이해가 아직 부족한 것 같아, 다시 정리해보고자 한다.
빅오 표기법(Big-O)
빅오 표기법은 불필요한 연산을 제거하여 알고리즘분석을 쉽게 할 목적으로 사용된다.
Big-O로 측정되는 복잡성에는 시간과 공간복잡도가 있는데
- 시간복잡도는 입력된 N의 크기에 따라 실행되는 조작의 수를 나타낸다.
- 공간복잡도는 알고리즘이 실행될때 사용하는 메모리의 양을 나타낸다.
요즘에는 데이터를 저장할 수 있는 메모리의 발전으로 중요도가 낮아졌다. - 아래는 대표적인 Big-O의 복잡도를 나타내는 표이다.
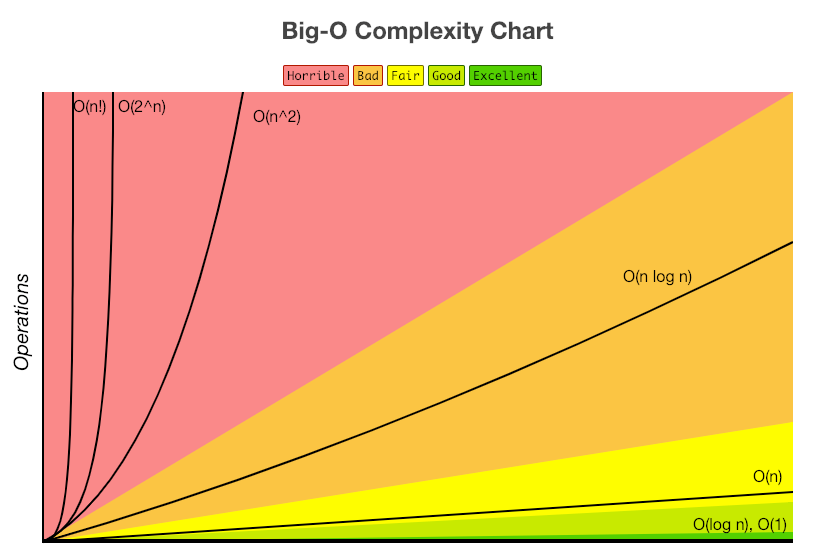
- 데이터 수 대비 시간의 증가율을 그래프로 그려보면 각 연산의 복잡도가 각각의 그래프와 유사하게 증가함
- 시간복잡도 : O(1) > O(logn) > O(n) > O(n2)
시간복잡도
- 입력되는 데이터의 증가에 따른 성능의 변화를 예측
- 알고리즘이 n개의 데이터에 대해 얼마나 많은 연산을 수행하는지 (= 알고리즘의 성능)
- 증가하는 n에 대한 성능의 변화율
- 정확한 측정값이 아님
- 정확한 연산의 횟수가 아니라, n의 갯수에 따라 연산이 증가하는 비율을 의미 (명령어의 실행시간은 컴퓨터의 하드웨어 또는 프로그래밍 언어에 따라 편차가 크게 달라지기 때문에 명령어의 실행 횟수만을 고려)
// n의 단위
1 O(1) --> 상수
2n + 20 O(n) --> n이 가장 큰영향을 미친다.
3n^2 O(n^2) --> n^2이 가장 큰영향을 미친다.// 시간복잡도의 문제해결 단계
O(1) – 상수 시간 : 문제를 해결하는데 오직 한 단계만 처리함.
O(log n) – 로그 시간 : 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어듬.
O(n) – 직선적 시간 : 문제를 해결하기 위한 단계의 수와 입력값 n이 1:1 관계를 가짐.
O(n log n) : 문제를 해결하기 위한 단계의 수가 N*(log2N) 번만큼의 수행시간을 가진다. (선형로그형)
O(n^2) – 2차 시간 : 문제를 해결하기 위한 단계의 수는 입력값 n의 제곱.
O(C^n) – 지수 시간 : 문제를 해결하기 위한 단계의 수는 주어진 상수값 C 의 n 제곱.실행시간이 빠른순으로 입력 N값에 따른 서로 다른 알고리즘의 시간복잡도
| Complexity | 1 | 10 | 100 |
| O(1) | 1 | 1 | 1 |
| O(log N) | 0 | 2 | 5 |
| O(N) | 1 | 10 | 100 |
| O(N log N) | 0 | 20 | 461 |
| O(N^2) | 1 | 100 | 10000 |
| O(2^N) | 1 | 1024 | 1267650600228229401496703205376 |
| O(N!) | 1 | 3628800 | 화면에 표현할 수 없음 |
O(1) : 상수
아래 예제 처럼 입력에 관계없이 복잡도는 동일하게 유지된다.
int func1(int[] n) {
if (n.length < 3) {
return 0;
}
int a = n[0];
a += n[1];
a += n[2];
return a;
}O(N) : 선형
입력이 증가하면 처리 시간또는 메모리 사용이 선형적으로 증가한다.
int func1(int[] n) {
int s = 0;
for (int i : n)
s += i;
}
return s
}O(N^2) : Square
반복문이 두번 있는 케이스
void bubbleSort(int[] n) {
for (int i = 0; i < n.length; i++) {
for (int j = 0; i < n.length; j++) {
if (n[i] < n[j]) {
int temp = n[j];
n[j] = n[i];
n[i] = tmep;
}
}
}
}O(log n) O(n log n)
주로 입력 크기에 따라 처리 시간이 증가하는 정렬 알고리즘에서 많이 사용된다.
int sum(int[] n) {
int sum = 0;
int max = n.length;
while (mzx > 0) {
sim += n[max - 1];
max /= 2;
}
return sum;
}
// 배열의 길이가 n개일때, 연산을 수행하는 횟수는 절반씩 감소시간복잡도를 구하는 요령
각 문제의 시간복잡도 유형을 빨리 파악할 수 있도록 아래 예를 통해 빠르게 알아 볼수 있다.
- 하나의 루프를 사용하여 단일 요소 집합을 반복 하는 경우 : O (n)
- 컬렉션의 절반 이상 을 반복 하는 경우 : O (n / 2) -> O (n)
- 두 개의 다른 루프를 사용하여 두 개의 개별 콜렉션을 반복 할 경우 : O (n + m) -> O (n)
- 두 개의 중첩 루프를 사용하여 단일 컬렉션을 반복하는 경우 : O (n²)
- 두 개의 중첩 루프를 사용하여 두 개의 다른 콜렉션을 반복 할 경우 : O (n * m) -> O (n²)
- 컬렉션 정렬을 사용하는 경우 : O(n*log(n))
출처
'Computer Science' 카테고리의 다른 글
| [HTTP] 모든 개발자를 위한 HTTP 웹 기본 지식(강의) 정리 (0) | 2023.02.04 |
|---|

댓글