영어 발표 스터디를 하고 있다. (참고로 OMEP: Oh My English Present 는 사실 내가 그냥 지은 이름이다.) 내 발표들을 다시 정리해두면 좋을 것 같아, 블로그에도 업로드한다.
There's an interesting article that I recently read about JSON, which is a format that I use a lot, and the author argues that JSON is garbage, and it's a really interesting read, and if you've ever used JSON, it's a fun read that will make you think twice about data formats and look back at the JSON that you've been using unconsciously. So let's get started with the presentation.
JSON started as (almost) a subset of JavaScript and is now a very popular serialization format across languages. Virtually every programming language has a JSON library. (There are even JSON libraries that run on the Apple II, which predates JSON by about 30 years.)
Before I start my presentation…
*In fact, I was going to do a comparison with an article that lists the benefits of JSON, but it mostly just talks about things like it's better than XML and it's human readable, so I focused on the things that aren't so great about it.
the writer saids JSON is a prime example of how poorly thought out standards can lead to serious problems.
not efficient
JSON is intended to be a subset of JavaScript, so it is inherently human-readable. However, in general, serialization formats are designed for performance and not for human readability (which is not to say that they are human-friendly). JSON is a very inefficient format, and performance was never considered in its design.
- The sizes of strings, arrays, and objects are not specified anywhere, so it's impossible to skip parts of the data without reading them. JSON must be read in order from start to finish in order to parse it correctly.
- There is always the possibility of an escape sequence in the string. This means that even if you know the end of the string, you'll still need to reprocess it to get the actual string.
- Numbers can only be represented in the decimal system. In particular, the decimal conversion of floating-point numbers cannot be made to perform well without numerical analysis and extreme algorithmic rigor. To be fair, the floating-point to decimal conversion algorithm itself is an evolution of JSON.
- The data model is missing binary bytes, requiring additional encoding. Despite this inefficiency, JSON survived almost purely because it had an even more inefficient antithesis in [XML] (https://hut.mearie.org/xml/), and as a bonus, it could be written directly in JavaScript.JSON Data Model from https://hevodata.com/learn/json-modeling/
Counterarguments→ but Aren't JSON implementations efficient these days?
You might argue that JSON was inefficient in the past, but modern implementations like RapidJSON and simdjson are efficient. While there is some truth to this, it's not a fair comparison.
What these implementations have in common is that they split JSON structure analysis and tree generation. Using [1, 2, 3] as an example, structure analysis is figuring out that this is an array of three numbers at offsets 1, 4, and 7
tree generation is actually getting the array type of your language from it. And the enormous performance of these implementations is limited to the structural analysis performance.
It's also hard for humans to use.
Performance aside, some people value the fact that it's a human-readable format. However, JSON is still stuck in the old JavaScript (ECMAScript 3) syntax and has its own limitations that JavaScript doesn't have, making it a less human-friendly format.
- Unlike JavaScript, you can only write unconditional double quotes (") in a string.
[
{
"name": "Jane Doe",
"favorite-game": "Stardew Valley",
"subscriber": false
},
{
"name": "John Doe",
"favorite-game": "Dragon Quest XI",
"subscriber": true
}
]
const profiles = [
{
name: 'Jane Doe',
'favorite-game': 'Stardew Valley',
subscriber: false
},
{
name: 'John Doe',
'favorite-game': 'Dragon Quest XI',
subscriber: true
}
];
- You can't put newline characters in a string. You must use an escape string.
- If you want to use a Unicode scalar value greater than U+FFFF in a string as an escape string, you must use an unconditional intergate pair (U+10000 → \\\\ud800\\\\udc00).
- You can't use commas (,) after the last element of arrays and objects.
- As mentioned earlier, you can't write numbers in any base other than decimal.
- You can't write comments at all. To write a comment, you must write a key that is not used on the object, such as "_comment": "comment content", which is a ridiculous suggestion that has been passed around as a tip.
The problem is that despite this, it's often misused as a configuration format because it's human readable anyway. And when JSON is used as a configuration format, most of the time it's a proprietary extension that solves the above problems. Naturally, there have been many attempts at standardization, but none of them have resulted in a unified proposal. The most recent attempt at standardization can be found in RFC 8785.
The data model is weird
A data model is a logical data type that results from interpreting a serialization format.
For example, if the format has "numbers", then things like the acceptable range of those numbers would be properties of the data type. Whether there is a distinction between "Unicode strings" and "binary bytes" would also be a matter for the data model.
The data model for JSON is not well define. at best we can say "JavaScript-like semantics if unambiguous". This is not much further along than RFC 8259, which is just a bunch of guesses about how implementations will probably react to these values.
JavaScript has had a guarantee since ECMAScript 1 that numbers are IEEE 754 binary64 (double precision), but JSON has no such guarantee, so the following questions cannot be answered at all from a JSON specification.
- If I write 1e400, should I get an error or infinity? → What if 1e-400? → What about 0e99999999999999999999999999?
- If I write 0.1, is it guaranteed that this value is exactly 3602879701896397/255, or how far off can I be? → Even if there is no guaranteed error, are we at least guaranteed that the two values are the same when we write [0.1, 0.1]?
- Is 30000000000000001 different from 30000000000000000? The former cannot be represented in binary64, which is why Twitter has changed its API format before
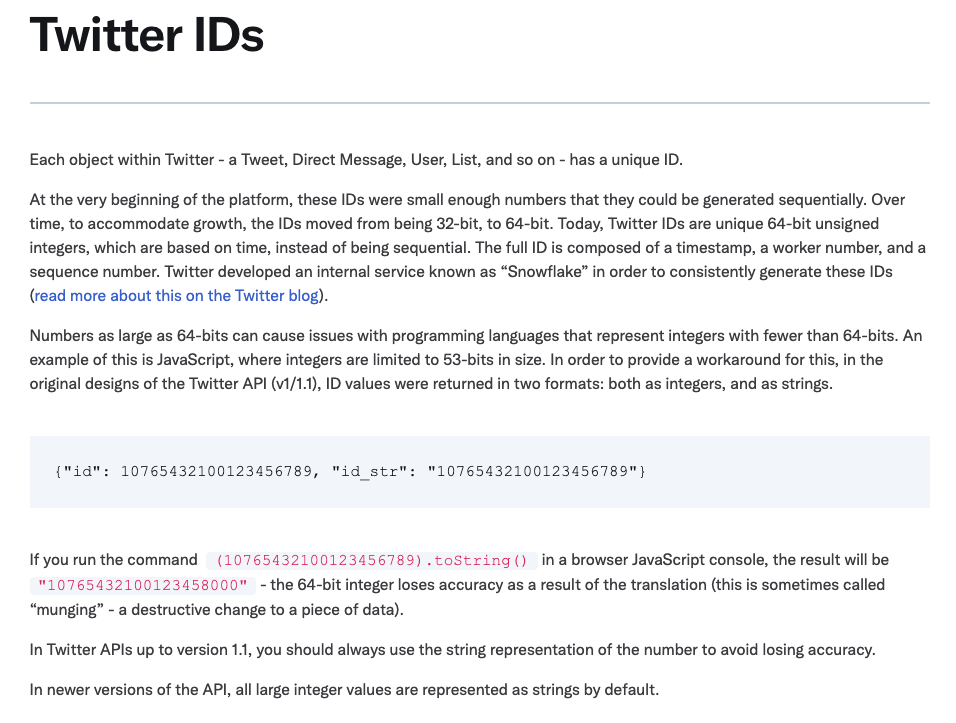
- Is there a range limit for non-decimal integers? Some JSON implementations use the presence or absence of a decimal point to determine whether to write an integer or a real type, which typically has a range around ±231 or ±263, which does not match the range of a real type. Therefore, integers larger than ±231 may misbehave in some implementations, even if they can be represented as real numbers.
Alternatives
There is no way to completely avoid JSON in modern programming. Regardless of the problems with JSON, it's a popular format and you're going to have to use it whether you like it or not. If you meet the following conditions, using JSON shouldn't cause you any problems.
- Your data is small and you don't decode it very often.
- You can guarantee that every number is an integer with an absolute value less than 231. If they are larger than that or have decimal points, you can use a string instead.
- Not used as part of a security protocol.
- Should support as many environments as possible. Of course, if you can avoid it, avoiding JSON is probably a good choice.
so i got some schemaless byte-oriented binary serialization format repository.
Comparison of schemaless byte-oriented binary serialization format
if you are trying to avoid JSON it might be another choice for you.
'Study' 카테고리의 다른 글
| [Study | OMEP] week 10: generate AI and Vercel v0 (1) | 2023.11.25 |
|---|---|
| [Study | OMEP] week 7: Prompt Engineering Guide (1) | 2023.10.29 |
| [Study | OMEP] week 4: Celebrating SQLite’s 23rd birthday: why we love it (0) | 2023.10.08 |
| [Study | OMEP] week 2: Figma for developers (0) | 2023.10.08 |
| [Study | OMEP] week 1: the basics of redis (0) | 2023.10.08 |




댓글